
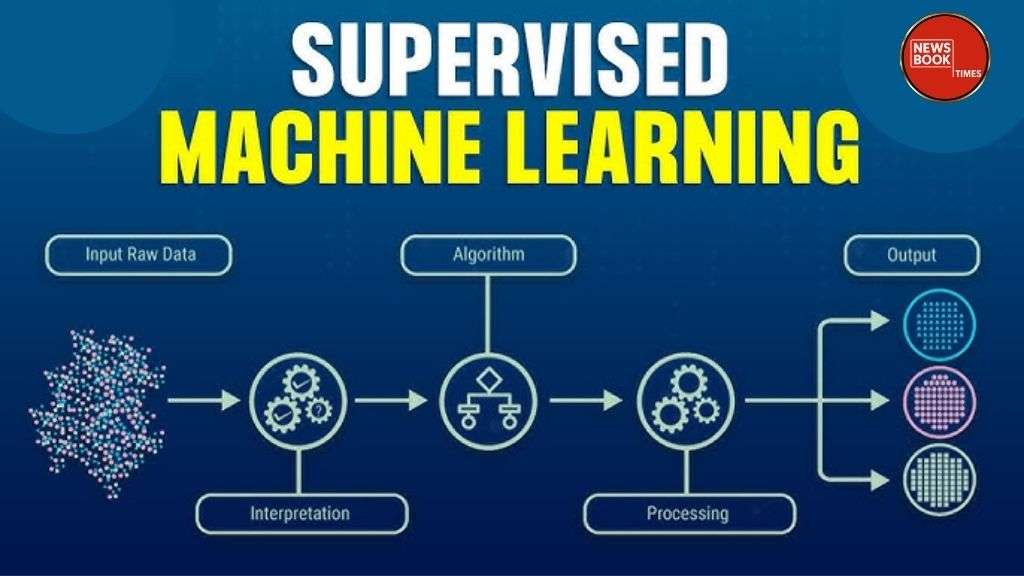
Supervised Machine Learning is a method that allows computers to learn by observing a data set that already contains the correct answer. This labeled data guides the machine through a step-by-step process, helping it understand how different pieces of information are related. When a computer is trained using such organized samples, it becomes capable of recognizing patterns, identifying differences, and making predictions with confidence. That sounds complex, but as soon as we start to understand how the machine learns with structured guidance, it becomes quite simple to understand.
In this approach, the computer does not need to make any guesses on its own. Instead, each training example consists of input and its corresponding output, ensuring precise and controlled learning. Therefore, Supervised Machine Learning is one of the most successful ways to train machines. Essential elements such as training data, learning algorithms, pattern discovery and predictive accuracy, work together to improve the system with each round of learning.
How the Machine Actually Learns
To Understand it more accurately, take an example of a medical laboratory that has been storing patient reports. Every report includes the symptoms, testing results, and diagnosis as written by a physician. These are referred to as labelled since they’re equipped with the proper names of diseases. When such reports are fed to a machine, it studies relationship between symptoms and illness. Over time, it learns which patterns correspond to which diagnosis. Once trained, the machine will be able to predict possible illnesses when it receives a new report. This is the process that Supervised Machine Learning uses: “labeled” information with new situations accurately.
This learning method depends strongly on the input-output pattern. The machine continues to recognize patterns and compare results, correcting its mistakes and refining its accuracy. Terms such as data categorisation, feature identification, training cycles, model tuning, and prediction quality accurately describe how the machine becomes more reliable over time. While machines do not understand meaning as a human does, they operate under mathematical rules that enable them to act intelligently when given new information.
Why This Learning Method Matters Today
Data drives the digital world of today, and Supervised Machine Learning has been a powerful tool for understanding and utilizing the data. It can support industries in making effective decisions, understanding user habits, categorizing information, and predicting the future trends. Many of the services we rely on every day – recommendation systems, sorting tools, and decision-support apps, depend on this technique for smooth and intelligent functioning.
One of the primary reasons for its importance is accuracy. When machines learn from labeled examples, they deliver results that can be trusted more. For example, email systems classify messages and categorized into “important” and “not important”, based on profiles learned from labeled data. Likewise, apps recommending videos, songs, or products are based on patterns from user’s past activities.
Read Also: Features of Self-Aware AI
Types of Problems It Can Solve
There are two major types of problems solved by Supervised Machine Learning — classification and regression.
Classification is the process of categorizing data into distinct groups or categories. When machines determine whether something falls into category A or category B, they are performing a classification. Through training on labeled samples, the machine learns which features belong to each group, and then it can categorize new data into corresponding category.
Regression, however, is about predicting numerical values. If a company wants to estimate its upcoming monthly sales, it can use labeled past sales data. The machine learns how numbers have shifted over time by month and identifies patterns. It then makes predictions on future values using those patterns.
Both classification and regression demonstrate how Supervised Machine Learning helps machines to understand categories and numbers, making it widely applicable for real world use cases.
How It Improves Technology Around Us
Technology becomes more valuable and helpful when Supervised Machine Learning is applied correctly. It assists systems in identifying information rapidly, recognising patterns correctly, and making decisions wisely. Apps can better understand user preferences, industries can more effectively analyze risk, and organization can make informed decisions based on clear data insights. As the machine is trained with labeled information, its performance improves gradually over time.
It contributes to safety, quality, and efficiency. For example, industries use predictive systems to detect equipment issues early. Educational platforms analyze learning behaviour and suggest personalised study paths tailored to individual needs. Traffic-management tools analyze vehicle flow patterns. All these improvements become possible because machines have learned from highly-structured examples.
Read Also: Reinforcement Learning in Machine Learning
Conclusion
Supervised Machine Learning is a strong and well-established learning method that trains computers using labeled examples. It’s based on a simple idea: When machines are trained on data that has correct answers, they become much better at predicting new ones. With the help of one example of medical reports only, we can clearly see how the system learns patterns and applies them to new data.
From classification to regression, and from prediction to decision-making, Supervised Machine Learning has become a key technique that strengthens today’s digital world. As technology constantly advances, Supervised Machine Learning will remain at the core of developing accurate, intelligent and efficient systems.






